

Executive Summary
AI in accounts receivable uses machine learning, NLP, predictive analytics, and agentic AI to automate cash application, collections, credit risk, and disputes, delivering 25-40% DSO reduction, 99.2% match accuracy, and 4x collector capacity with payback in 6-9 months.
Key Takeaways from This Guide
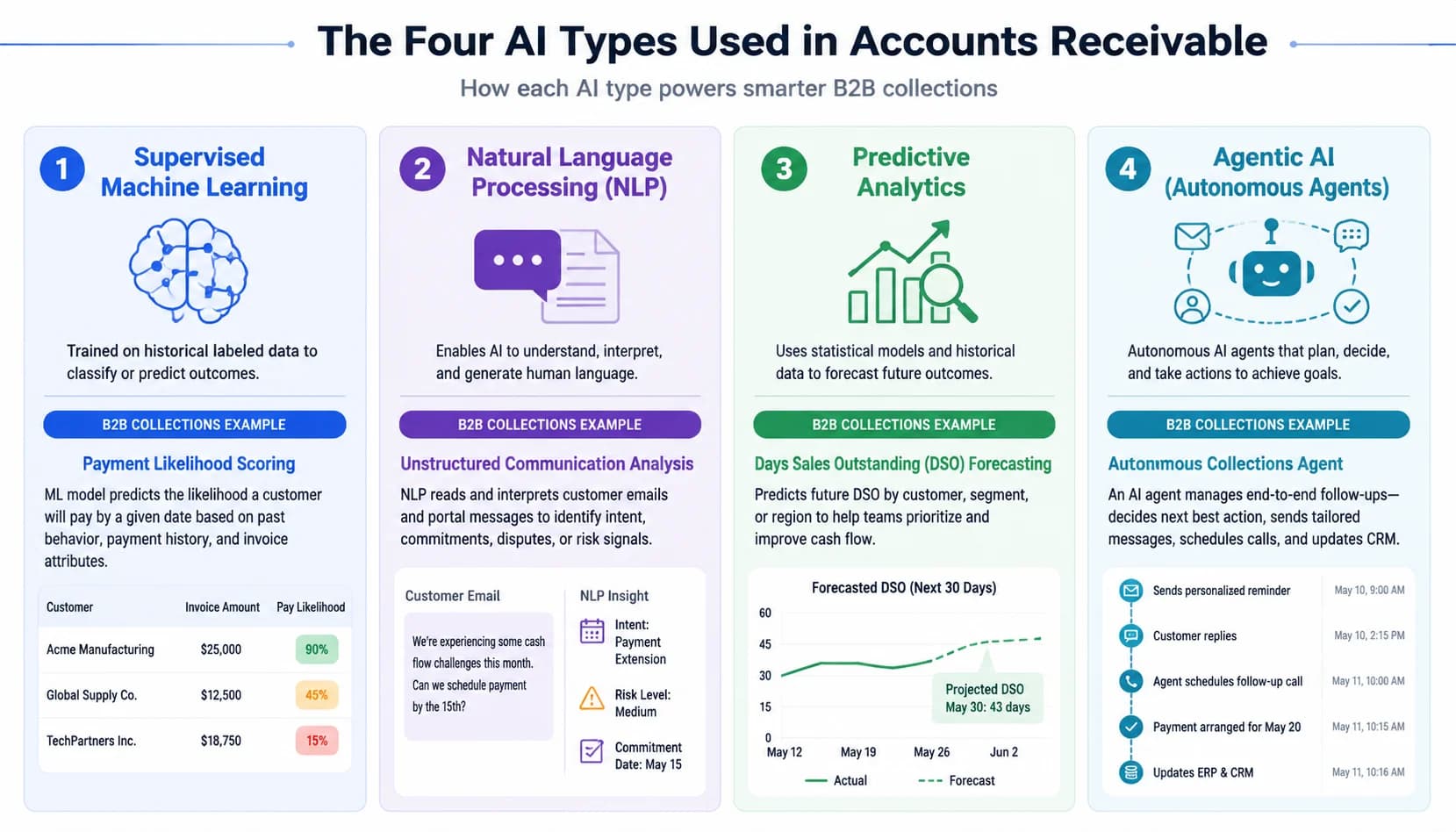
- Four AI types power AR (supervised ML, NLP, predictive analytics, agentic AI) and they are not interchangeable across cash application, collections, risk, and disputes.
- Mid-market teams using AI in AR cut DSO 25-40%, recover $440K and 4,500 analyst hours, and hit payback in 6-9 months (Forrester TEI 2024).
- AI raises collector capacity from 200-300 accounts to 800-1,200, giving roughly 4x leverage on existing headcount with no quality loss.
- Industry impact varies sharply: construction sees 40% faster retainage release, healthcare cuts denial rework 50%, SaaS automates 90% of dunning.
- Real AI vendors answer five mechanism questions on training data, model output, feedback loop, guardrails, and retrain cadence; if not, it is RPA in a marketing wrapper.
What AI in accounts receivable actually means
Your CEO walks into the Monday finance review and asks one sentence that ruins the rest of your week: "What is our AI strategy for finance?" Meanwhile, three AR vendors have pitched you something "AI-powered" this quarter, and 95% of finance teams in the 2025 Gartner AI in Finance survey already report measurable efficiency gains. The pressure to have a real answer is no longer optional.
The problem is that "AI in accounts receivable" has become a marketing wrapper that hides four very different technologies. Supervised machine learning, natural language processing, predictive analytics, and agentic AI each solve a different AR problem. Mixing them up is how mid-market finance leaders end up paying enterprise prices for a glorified rules engine that misses 30% of remittances on day one.
Start with the four AI types, because vendors blur them on purpose. Supervised machine learning powers cash application: it studies your last 18 months of matched invoices and learns which payment goes to which open AR. Natural language processing reads the messy free-text on a remittance email or check stub. Predictive analytics scores how likely a customer is to pay 30 days late. Agentic AI handles autonomous outreach, sending the second dunning email and rescheduling the next one based on the response.
Rules-based RPA is not AI, even though it shows up under the same booth at the trade show. RPA executes a script you wrote: if invoice equals payment to the cent, post it. The moment a customer short-pays by $12 for freight or sends one wire for three invoices, the rule fails and a human gets a queue ticket. Machine learning tolerates that fuzziness because it was trained on thousands of similar fuzzy cases. The difference is mechanism, not branding.
The stakes are why this matters now. In the 2025 Gartner AI in Finance study, 95% of finance teams using AI report measurable efficiency gains, and the median improvement is no longer marginal. Boards are asking for an AI strategy by name, and CFOs who cannot distinguish ML from RPA in a vendor pitch end up overpaying for under-built tools. For a broader view of how this fits into the wider automation stack, our [complete guide to AR automation](/blog/complete-guide-ar-automation) maps where AI plugs in alongside workflow, EIPP, and ERP layers.
Here is the practical test. Ask any vendor: which of these four AI types do you ship, and which AR workflow does each one own? If the answer is a single word ("AI") or a vague "all of them, end-to-end", you are looking at marketing, not mechanism. The next section unpacks how the most important of those four, supervised ML, actually works inside the system you are evaluating.
How machine learning works inside an AR system (in plain English)
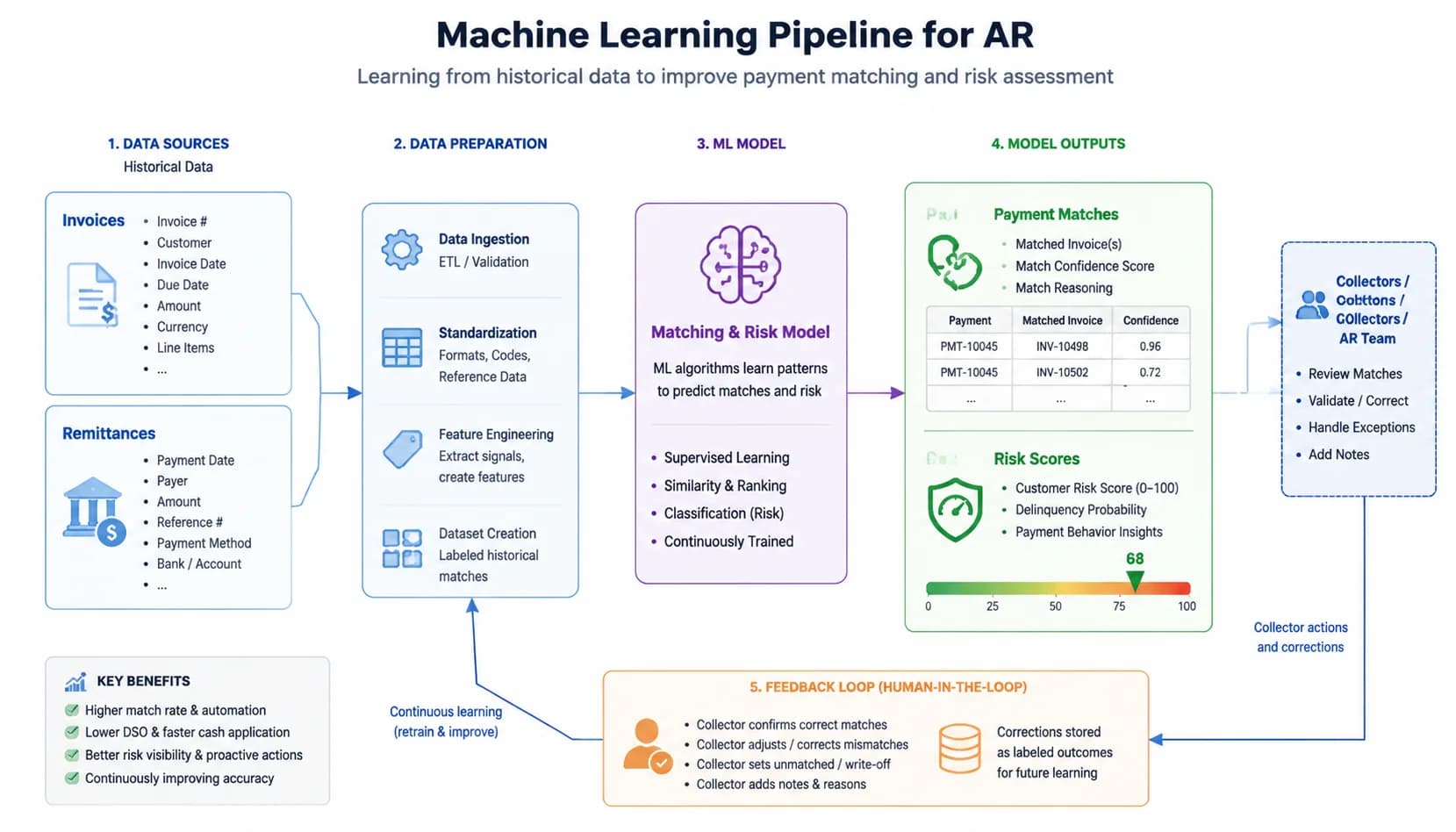
Walk through cash application as the worked example. The training data is your last 12 to 18 months of paired invoices and remittances: invoice 4471 for $8,212.50 was paid by wire 9921, even though the wire memo said "INV4471 less freight 12.50". You feed the model thousands of these pairs. It learns that customers in your wholesale segment short-pay freight by $12 to $18 routinely, that the memo field uses three common abbreviations, and that wires from one bank arrive grouped two days after invoice due date.
The model output is a ranked list of likely matches with a confidence score. A new wire arrives for $24,637.50. The system proposes invoice 4471 plus 4472 plus 4473, with a 97% confidence score, and posts straight through. A second wire for $11,402 looks like invoice 5180 minus a $98 deduction, but only at 71% confidence, so it routes to a collector with the proposed match pre-filled. The collector confirms or corrects in two clicks instead of reconciling from scratch.
This is where ML beats rules permanently. Rules choke on short-pays, multi-invoice wires, and remittance text the customer rewrites every quarter. ML tolerates all three because it was trained on the messy reality, not a tidy spec. Mid-market teams typically see straight-through match rates jump from 55-65% on rules to 92-99% on ML, which is why solutions like SINGOA's [AI payment matching](/features) hit 99.2% accuracy on production data rather than sandbox demos.
The feedback loop is the part most buyers miss. Every time a collector overrides a low-confidence suggestion ("actually that wire was for invoice 5181, not 5180"), the correction goes back into the training set. Next month the model knows that customer changed their numbering convention. A static rules engine would need a developer ticket and a release window for the same fix; ML closes the loop in days. That is how a 92% match rate in month one becomes 99% by month six.
What makes this work in practice is data quality, not model size. A clean 18-month history of one wholesale customer is worth more than a noisy three years across 40 customers. If your master data has duplicate customer records, missing ship-to codes, or inconsistent invoice formats, the model learns the noise. The first phase of any real AI-AR implementation is a data audit, and skipping it is the single largest cause of disappointing pilots.
Pro Tip
When a vendor says "AI-powered", ask three questions. What is the training data? What does the model actually output? How does it learn from collector corrections? If they cannot answer all three in plain language, you are looking at rules-based RPA in a marketing wrapper, not machine learning.
Six AR workflows where AI delivers measurable ROI today
Cash application is the workflow that pays for the rest of the program. Mid-market teams running ML against bank files and remittance emails typically move from 55-65% straight-through match rates to 92-99%. NLP reads unstructured remittance text (PDFs, emailed spreadsheets, lockbox image data) that rules engines cannot parse. PYMNTS 2024 reported that AI-driven matching cuts the average time-per-payment from 4.2 minutes of analyst work to under 30 seconds, with the rest of the time recovered for actual exception handling.
Smart collections prioritization tackles the Pareto problem. In any AR portfolio, roughly 20% of accounts drive 80% of overdue balance, but most teams still work the worklist alphabetically or by oldest aging bucket. ML scores every account on payment history, communication response patterns, invoice size, and seasonality, then surfaces the 50 calls that will move the most cash this week. For deeper context on the mechanism behind the match-rate numbers, see our [AI payment matching accuracy benchmarks](/blog/ai-payment-matching-accuracy) breakdown.
Credit risk scoring is the predictive piece that protects the next 90 days of cash. The model studies which customers paid 30 days late in the past, what changed in the weeks before (slower email response, bigger invoice size, industry headwinds), and flags new accounts that look the same. Catching a slow-payer 30-60 days ahead means tightening terms or asking for a deposit, instead of a write-off six months later. Bad-debt reductions of 15-25% are common in the Forrester sample.
Dispute classification handles the deduction backlog every wholesale and manufacturing CFO hates. Customers short-pay with reason codes that are inconsistent at best ("OS&D", "price", "PO mismatch") and missing at worst. NLP classifiers route 80%+ of incoming disputes to the right resolver in seconds, so a freight claim hits logistics, not the AR team that has to email logistics anyway. The cycle time on disputes drops from 18-25 days to 5-9 days in mid-market deployments.
Cash forecasting closes the loop for the CFO. Treasury teams running ML on historical payment timing data hit weekly inflow forecasts within 3-5% accuracy, versus the 12-18% error band typical of rolling-average spreadsheets. Forecast accuracy at that level lets you draw less on the revolver, which directly reduces interest expense, often more than the AI software costs in the first year.
Conversational AI rounds out the six. Customer payment portals with embedded NLP answer "when is my statement due?", "how do I update remit-to?", and "can I split this invoice?" without an AR ticket. Agentic AI handles the dunning sequence: send reminder one, log the response, schedule reminder two, escalate to a human at day 21. The 2024 Ardent Partners survey found teams using conversational and agentic AI fielded 60-70% of routine customer requests with no human touch. Those analyst hours move straight to enterprise account work.
What is AI worth to your AR team?
Plug in monthly invoice volume and current DSO to estimate the working-capital and headcount-leverage impact.
The quantified ROI: what AI in AR is actually worth
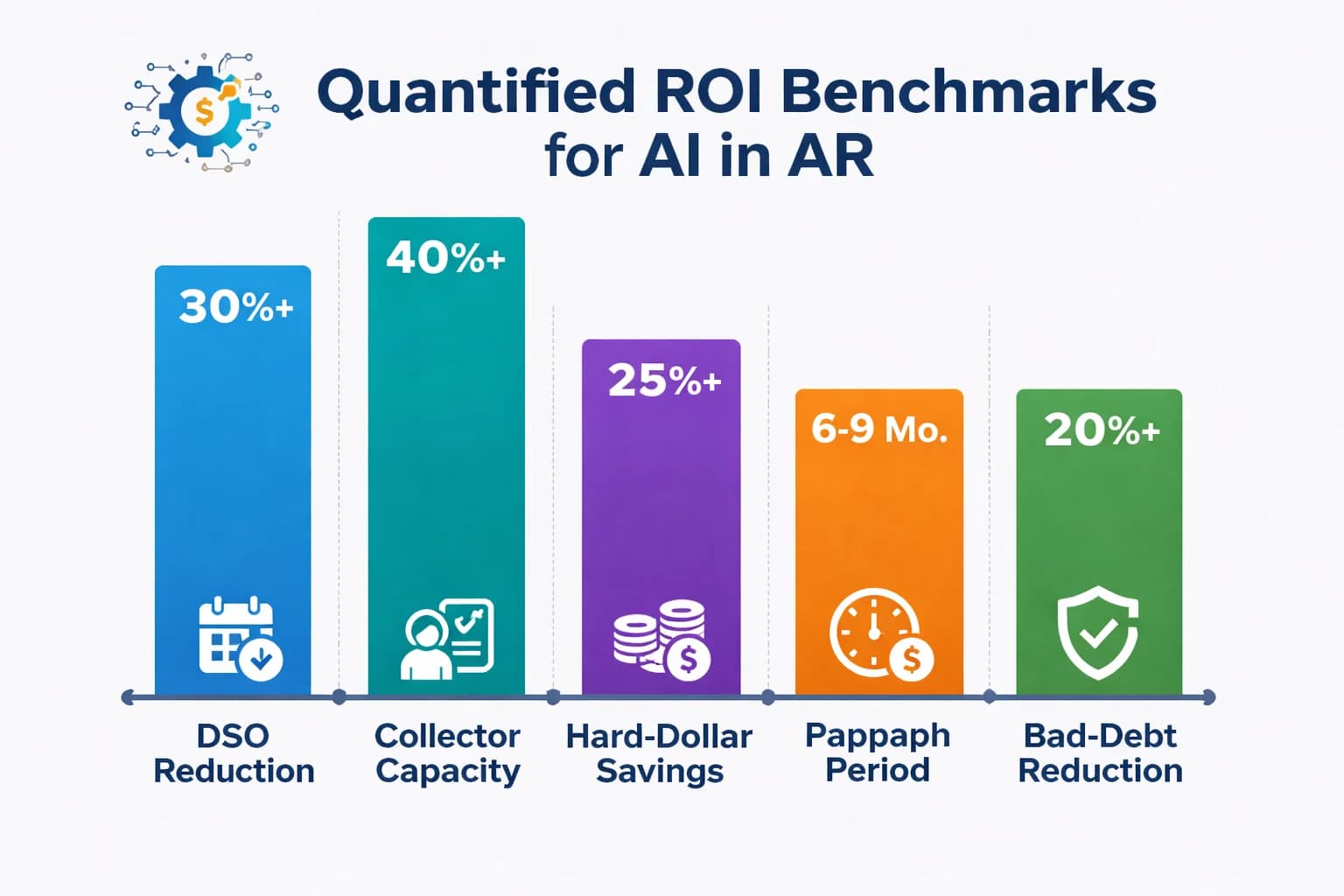
Start with DSO, because that is the number your CFO already tracks. The Forrester TEI sample of 12 mid-market deployments showed a 25 to 40% DSO reduction within 12 months of go-live. For a company carrying $40M in receivables at 60-day DSO, a 30% cut is roughly $4.8M in working capital released back to the business. At a 6% cost of capital, that is $288K in annual interest savings before you count the software value. Pair that math with our [DSO reduction strategies](/blog/reduce-dso-proven-strategies-2026) breakdown to see where AI fits versus credit policy and dunning cadence.
Headcount leverage is the part most ROI models underweight. A traditional collector covers 200 to 300 active accounts before quality degrades. With ML scoring, NLP remittance, and agentic dunning handling the routine 80%, the same collector now covers 800 to 1,200 accounts, roughly 4x the capacity. That is not a layoff story for most mid-market teams. It is a no-hire story: the same five-person AR team can support 4x the invoice volume as the company grows, which is why the ROI compounds across years two and three.
Hard-dollar savings land in the $440K range for the average mid-size deployment, with 4,500 analyst hours recovered annually (Forrester 2024). Those hours redirect from data entry and reconciliation to enterprise-account relationship work, which is precisely the work that protects renewal revenue. The savings split roughly 60% labor recovery, 25% bad-debt reduction, and 15% process cost (lockbox fees, postage, late-payment interest avoided).
Payback timeline is where AI-AR pulls clear of legacy ERP modules. Native Oracle or SAP AR enhancements typically run 12 to 24 months to payback, weighed down by long implementation and consulting costs. Purpose-built AI-AR platforms hit payback in 6 to 9 months because the cash-application lift is measurable inside the first 60 days. Pricing matters here too: at $1 to $3 per invoice, the cost scales with usage rather than seats, which keeps the math defensible at the board level.
Bad-debt reduction is the quiet line item that often surprises CFOs the most. Predictive risk scoring catches deteriorating accounts 30 to 60 days earlier than aging reports do, and the Forrester sample saw 15 to 25% reductions in net write-offs within the first year. For a $200M revenue business with 0.4% historical bad debt, a 20% cut is $160K straight to the bottom line, every year. Combined with the working capital release and the labor recovery, this is what makes the 6 to 9 month payback math work in practice rather than in slideware.
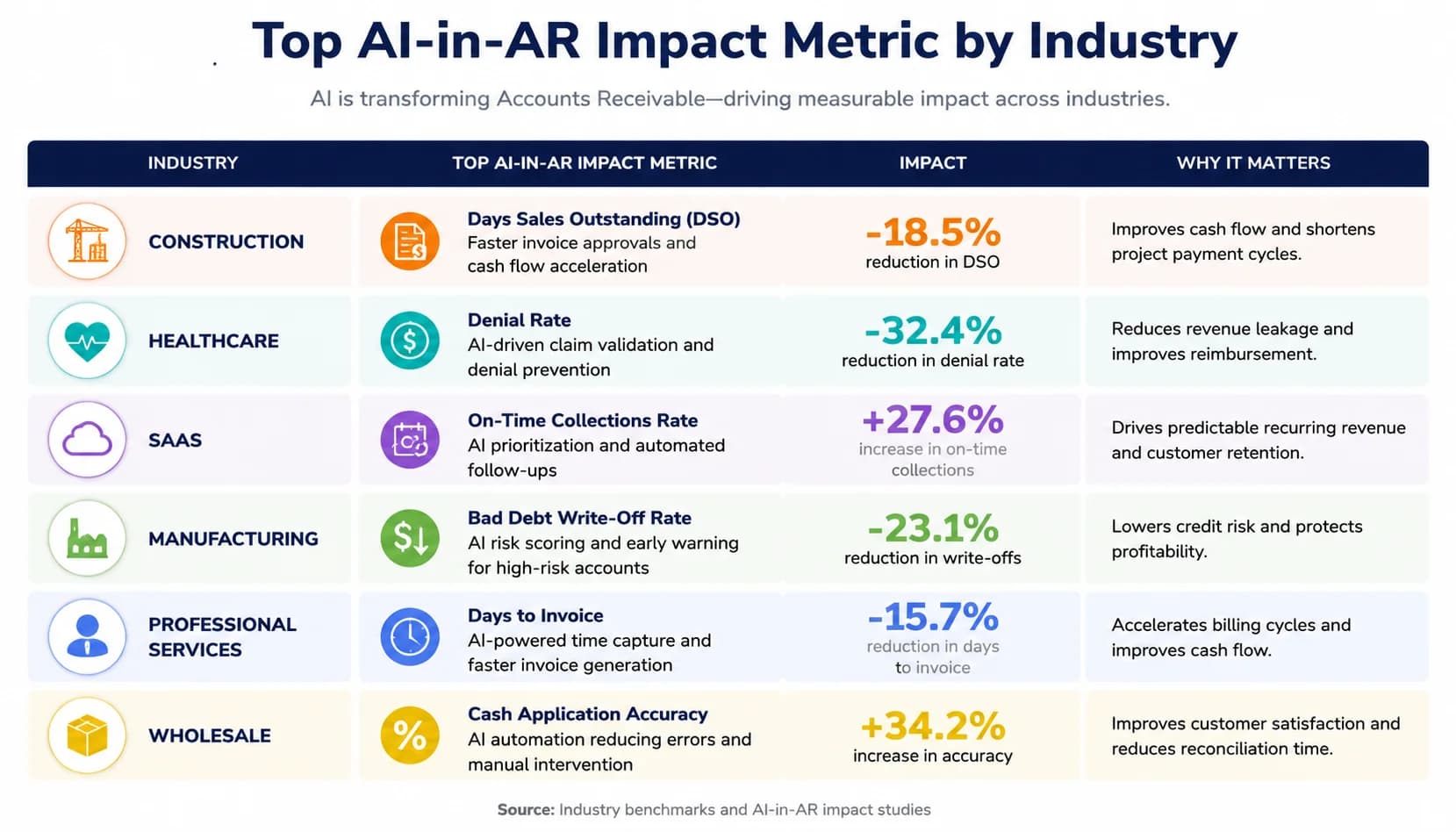
Industry-by-industry impact: where AI changes AR most
Construction is the industry with the most distinctive AR pain and the highest AI payoff. Pay applications, AIA G702/G703 forms, retainage holdbacks, and lien-waiver matching create a workflow where one project can have $400K stuck behind a missing notarized waiver. ML models trained on the firm's historical retainage release patterns flag the trigger conditions (substantial completion, punch-list closeout) 40% faster than manual tracking. For a deeper industry-specific walkthrough, see our [AI for construction AR](/industries/construction) playbook.
Healthcare AR runs on denials, not invoices. A claim hits the payer, comes back with a CARC or RARC reason code, and 30% of those denials are technically appealable but never get worked because the team is buried. NLP classifiers read the 835 remittance advice, route appealable denials to the right specialist, and pre-populate the appeal packet with the relevant clinical documentation. Provider groups using this approach in the 2024 Ardent Partners sample cut denial-rework cycle time 50%, recovering 6 to 9% of net revenue that previously aged out.
SaaS billing inverts the construction problem: invoices are simpler, but volume is enormous and usage-based metering creates billing disputes. Agentic AI handles 90% of dunning end-to-end, sending the friendly reminder, the firmer second notice, the credit-card retry on a failed charge, and the pause-service trigger at day 60. The customer success team only sees the 10% of accounts that actually need a human conversation, usually because of a renewal negotiation rather than a real payment problem.
Manufacturing lives on multi-PO short-pay reconciliation and trade-promotion deductions. A retailer pays for 47 line items across three POs, short-pays $12,400 against an OS&D claim, and applies a $4,200 marketing co-op deduction, all on one ACH. ML matches the line-level detail to the open invoices, NLP classifies the deduction reasons, and the AR team validates rather than reconstructs. Mid-market manufacturers in this profile typically see DSO drop 30% in the first year, with cash forecasting accuracy moving from +/-15% to +/-4%.
Professional services AR is engagement-letter driven, with bill rates varying by partner, jurisdiction, and matter. The hardest workflow is matching a client wire to the correct combination of WIP, billed time, and disbursements across three open invoices. ML trained on the firm's historical billing data resolves these in seconds and recovers an average of 4,500 analyst hours per year for mid-size firms (Ardent Partners 2024). Those hours redirect from billing reconciliation to actual matter management.
Wholesale and distribution wraps the picture with chargebacks and trade-promotion deductions. Big-box retailers ship deductions in batches, often citing reason codes that do not map cleanly to the supplier's chart of accounts. NLP classifiers reconcile the retailer's deduction language to the supplier's reason codes, and the team works the disputed deductions 3x faster. Net deduction recovery improves from the typical 18 to 22% baseline up to 35 to 45% on AI-assisted programs, which on a $50M wholesaler is $1.6M of recovered margin annually.
The pattern across all six industries is the same: AI does not change what AR is, it changes which 10% of the work needs a human. The training data has to match the industry, which is why a vendor demo on generic invoices proves nothing about your real numbers.
Where AI does NOT help (yet): the honest limits
Enterprise account escalations are the workflow where AI should stay out of the way. When your top-five customer is 47 days late on a $1.2M invoice and the controller has known the GM for nine years, the right move is a phone call, not an automated dunning email. Mid-market AR teams that route every account through agentic AI by default damage the relationships that protect the largest receivables on the book. The rule of thumb is to carve out the top 10 to 20 accounts manually and let humans own them.
Multi-party disputes with legal nuance are the second hard limit. A construction lien dispute that involves a general contractor, a sub, an owner, and a surety has documents AI cannot reliably interpret. The same is true for healthcare denials that require clinical judgment about medical necessity, or wholesale chargebacks that hinge on negotiated terms outside the standard reason-code taxonomy. AI accelerates the routine 80%; it does not resolve the legally ambiguous 20%, and pretending otherwise creates compliance risk.
Novel contract terms break the model in ways buyers rarely test for. ML predictions are reliable inside the distribution of historical data, and they degrade fast outside it. Sign a new master agreement with terms your model has never seen (a milestone-based payment schedule on a usage-based product, or a co-investment clause with claw-back triggers) and the model's confidence stays high while its accuracy collapses. Mature AI-AR programs route any account on a non-standard contract to human review until the model has 90 days of fresh data on it.
The cold-start problem is the limit nobody warns you about. AI in AR needs roughly 12 to 18 months of clean training data to perform well. If your master data is messy, customer records are duplicated, or your ERP has been migrated twice in the last two years, the model learns the noise. Hallucination risk is the related concern on customer-facing copy: an agentic dunning email that invents a discount or a wrong due date is worse than no email at all. Our [guardrails for AI hallucinations in AR](/blog/ai-hallucinations-ar-automation-cfo-guide) playbook covers the specific controls that prevent it.
Pro Tip
Treat AI as a force-multiplier on your top two collectors, not a replacement for your top two collectors. The 10 to 20% of accounts that need human judgment is exactly where you want them spending their time, and the 80% AI handles is exactly where you do not.
Test our AI on your remittances
Send us your last 1,000 remittances. We will run them through SINGOA and show you the match accuracy on your real data, not a sandbox.
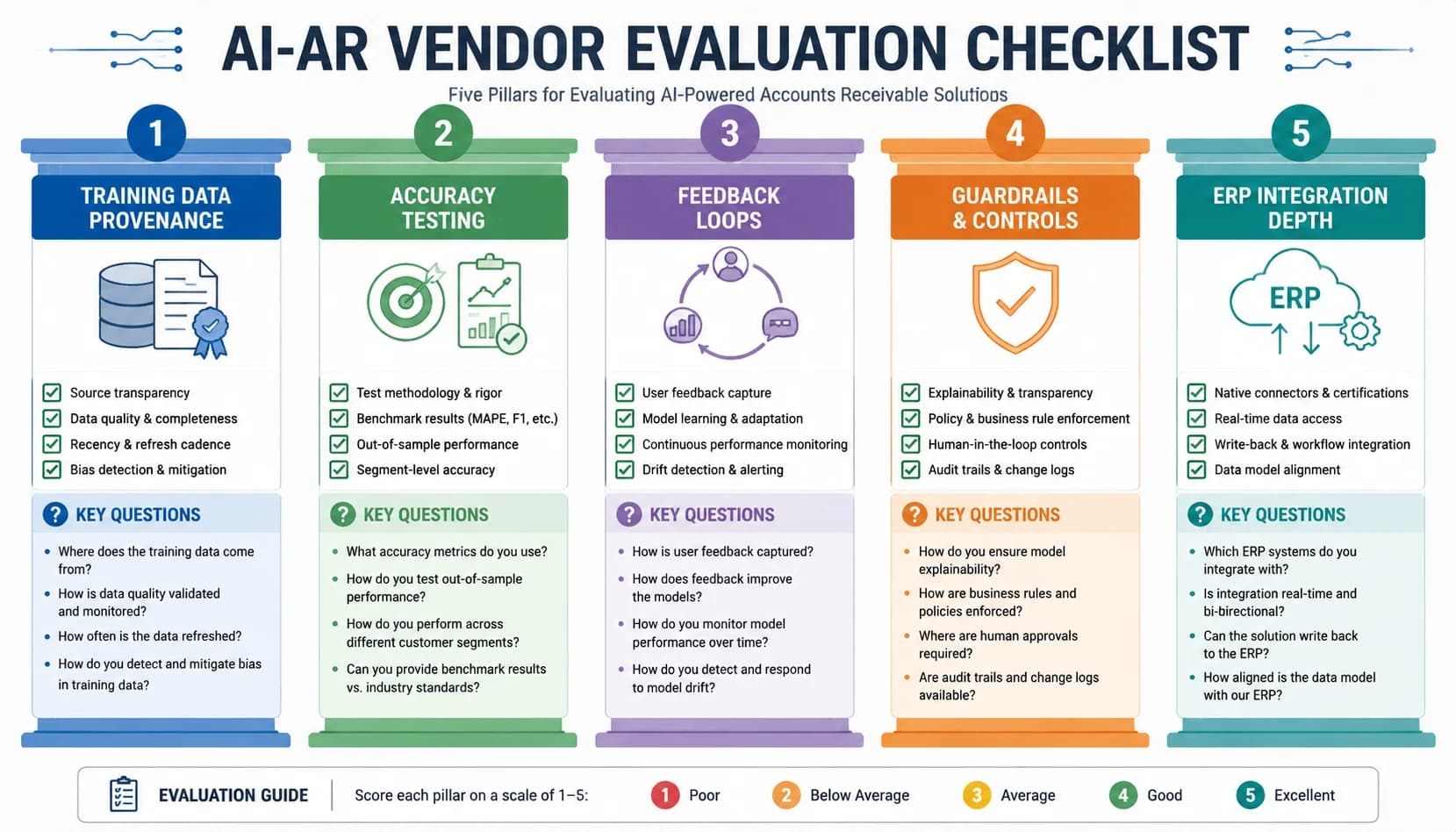
Vendor-evaluation framework: how to test AI claims before signing
Demand a live test on your last 1,000 remittances, not the vendor's curated demo dataset. This single requirement filters 60% of the market on the first call. Real AI-AR products will run your file through their model in 48 hours and return a confidence-scored match report. Vendors who refuse, ask for an extra fee, or want six weeks of "data prep" are usually shipping rules engines that need hand-tuning per customer. The accuracy on your real data is the only number that matters at signature time.
Ask the five mechanism questions and watch how cleanly each is answered. What is the training data, customer-specific or pooled? What does the model output, a single match or a ranked list with confidence scores? How does the feedback loop close the loop on collector corrections? What guardrails prevent hallucinations on customer-facing copy? What is the retrain cadence, daily, weekly, monthly? Real product teams answer all five in plain English; marketing teams pivot to case studies and brand names.
Validate ERP integration depth, because this is where AI projects quietly fail. A bidirectional, near-real-time sync against your specific ERP version (NetSuite 2024.2, SAP S/4HANA 2023, Sage Intacct, Microsoft Dynamics 365 F&O) is non-negotiable. Nightly CSV exports might look like integration in a demo and feel like integration on day one. By month three, a mismatched customer record in NetSuite throws every match recommendation off and the team reverts to spreadsheets. Drill into the [ERP integration depth](/integrations) details before signing.
Check the implementation timeline carefully. AI-AR products with mature self-serve onboarding hit production in 4 to 8 weeks, with first measurable cash-application lift inside 60 days. Anything over 12 weeks is a red flag, not a sign of thoroughness. Long timelines usually mean heavy custom-rules engineering, which is the opposite of machine learning, and it tells you the model needs human-coded handholding on every new customer. The vendor's median go-live time across their last 10 customers is the right metric to ask for.
Reference customers must match your size, industry, and AR complexity. A platform with great references at $5B enterprises is not necessarily the right fit for a $40M wholesale distributor, and vice versa. Ask for two references in your revenue band, two in your industry, and one with a multi-entity ERP setup that mirrors yours. Real platforms like SINGOA support this by pre-running a free remittance test on your data before any contract conversation, so you see the match accuracy on your file rather than a sandbox.
Pricing transparency is the final filter. Per-invoice pricing in the $1 to $3 range scales with usage, and the math stays defensible whether you are at 5,000 or 50,000 invoices a month. Per-seat enterprise contracts with $80K+ annual minimums are a flag for legacy architectures that do not actually need the AR volume to drive their cost. The pricing model tells you what kind of company you are about to do business with for the next three years.
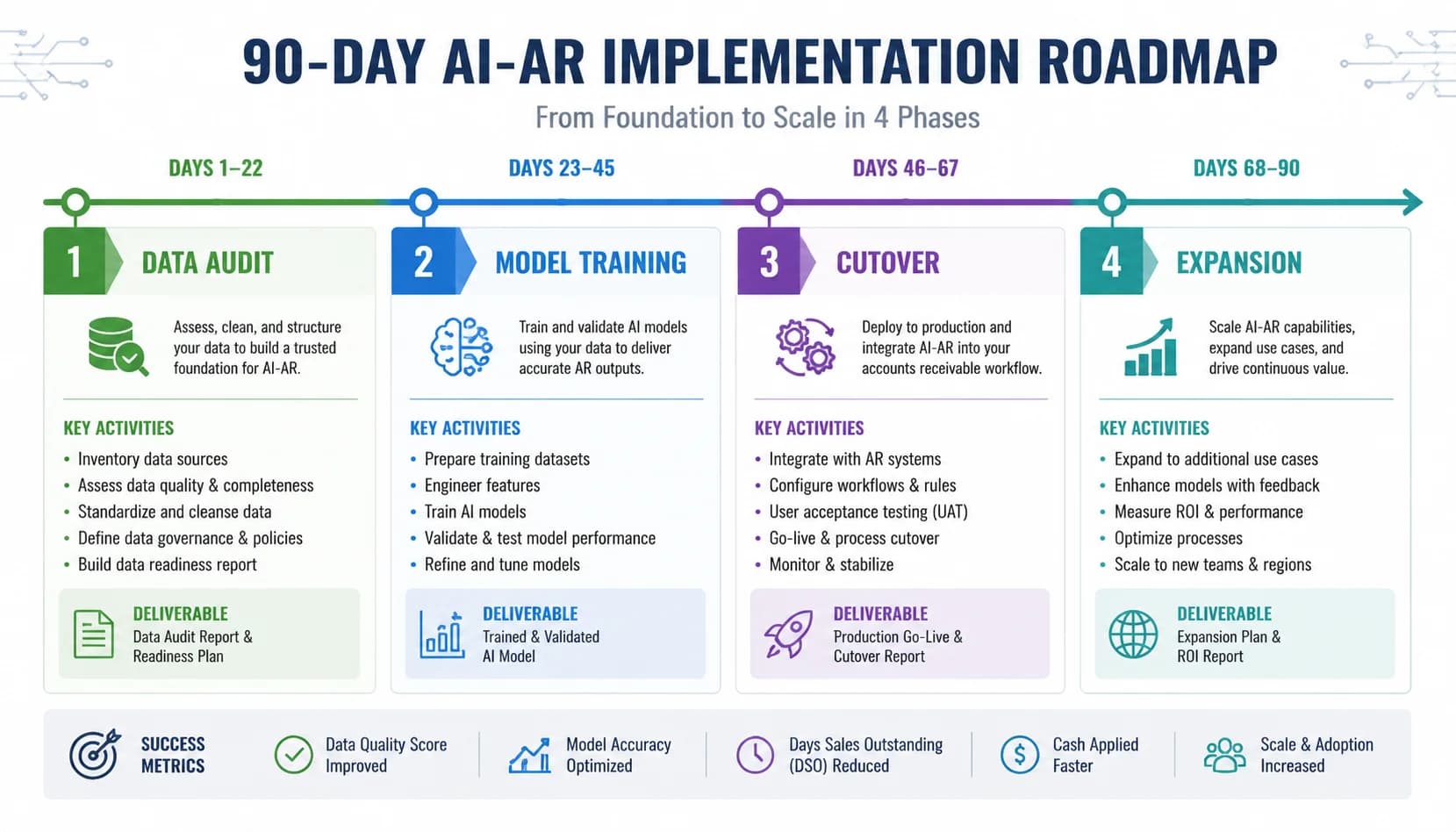
Implementation roadmap: 90 days from kickoff to first AI-driven cash
Phase 1 runs weeks 1 to 4 and is data work, not technology work. The team audits master data (duplicate customer records, missing ship-to codes, inconsistent invoice numbering), connects the ERP via the vendor's bidirectional sync, and locks success metrics with the CFO. The metrics that matter are straight-through match rate, DSO, collector capacity, and forecast accuracy, with a baseline measured the week before kickoff. Skipping the data audit is the single largest cause of disappointing pilots, because the model learns whatever it sees.
Phase 2 runs weeks 5 to 8 and is where the model learns your specific business. The vendor trains supervised ML on 12 to 18 months of your matched invoices and remittances, and runs the model in shadow mode against the live process. Shadow mode means the model produces match recommendations and risk scores, but the AR team still works the queue manually, comparing the AI suggestions to their own answers. Most teams hit 92 to 95% match accuracy in shadow mode by week 8, with the remaining gap closed by collector corrections feeding the loop.
Phase 3 runs weeks 9 to 12 and is the cutover. Auto-post low-risk matches above the confidence threshold (usually 95%), route lower-confidence matches to collectors with the proposed match pre-filled, and turn on the smart-collections worklist with the new prioritization. Collector training is two hours, mostly on how to give corrective feedback, because the workflow is simpler, not more complex. Dashboards go live for the controller and CFO showing match rate, DSO trend, and collector capacity by week.
Phase 4 covers months 4 to 6 and expands the program beyond cash application. Dispute classification turns on once the team has tagged 60 to 90 days of disputes by reason code. Predictive risk scoring turns on as soon as the model has scored a full payment cycle. Conversational AI for customer self-service typically waits until month 6, after the internal team is comfortable with the agentic dunning workflow. By the end of month 6, all six AI workflows are live and the ROI math from Forrester (25 to 40% DSO, 4x capacity, $440K savings) starts to materialize. For the broader picture of how this scales without new hires, see [scale AR operations without adding headcount](/blog/scale-ar-operations-without-adding-headcount).
The two failure modes to avoid are dirty master data and missing executive sponsorship. Dirty master data means the model learns noise, and the project loses credibility in week 6 when the match rate plateaus. Missing executive sponsorship means the AR team treats the AI suggestions as optional, the feedback loop never closes, and the model never gets past month-one accuracy. Both are preventable with a 30-minute weekly steering call run by the CFO for the first 90 days.
AI in accounts receivable is no longer an experimental conversation. It is four specific technologies (supervised ML, NLP, predictive analytics, and agentic AI) solving four specific AR problems, with quantified outcomes the CFO and AR manager can both defend. The teams pulling ahead are not the ones with the biggest budgets. They are the ones who learned to tell mechanism apart from marketing.
The playbook is straightforward. Start with cash application, because that is where the ROI math pays for the rest of the program. Layer in collections prioritization and risk scoring once the data feedback loop is closing weekly. Save agentic AI for month 4 or later, after your team trusts the matching and the guardrails are tested on real customer-facing copy. Carve out your top 10 to 20 enterprise accounts for human collectors, and let AI buy them back the time they need to actually work those relationships.
The 90-day implementation roadmap is real, the 25 to 40% DSO reduction is real, and the 6 to 9 month payback is real, but only if you pick a vendor who can answer the five mechanism questions on your data, not theirs. The next step is running a real test on your last 1,000 remittances and seeing the match accuracy on your file before any contract conversation.
90-day AI-AR implementation roadmap
Phase 1: Data audit and ERP connection
Weeks 1-4Data work, not technology work. Audit master data, connect the ERP via bidirectional sync, and lock success metrics with the CFO before any model training begins.
- Audit master data for duplicate customer records, missing ship-to codes, inconsistent invoice numbering
- Connect ERP via vendor bidirectional sync (NetSuite, SAP S/4HANA, Sage Intacct, Microsoft Dynamics 365 F&O)
- Lock baseline metrics with CFO: straight-through match rate, DSO, collector capacity, forecast accuracy
- Schedule the 30-minute weekly steering call for the first 90 days
Phase 2: Model training and shadow mode
Weeks 5-8Vendor trains supervised ML on 12 to 18 months of paired invoices and remittances, then runs the model in shadow mode against the live process while the AR team continues to work the queue manually.
- Train supervised ML on 12-18 months of matched invoices and remittances
- Run model in shadow mode alongside the live AR process
- Compare AI match recommendations to collector decisions for accuracy benchmarking
- Target 92-95% match accuracy in shadow mode by week 8
Phase 3: Cutover and collector workflow
Weeks 9-12Auto-post high-confidence matches, route lower-confidence to collectors with proposed match pre-filled, and turn on smart-collections worklist with new prioritization.
- Auto-post matches above the 95% confidence threshold
- Route lower-confidence matches to collectors with proposed match pre-filled
- Activate the smart-collections worklist with ML-driven prioritization
- Train collectors (2 hours) on how to give corrective feedback to the model
- Launch dashboards for controller and CFO showing match rate, DSO trend, and collector capacity
Phase 4: Expansion to disputes, risk, conversational AI
Months 4-6Expand beyond cash application as the data feedback loop matures. Dispute classification, predictive risk scoring, and conversational AI come online sequentially.
- Activate dispute classification once 60-90 days of reason codes are tagged
- Activate predictive risk scoring once the model has scored a full payment cycle
- Activate conversational AI for customer self-service in month 6
- Validate full ROI math: 25-40% DSO reduction, 4x collector capacity, $440K savings


